11 Stratégies RAG pour optimiser vos Agents IA en 2026

Connaissez-vous les principales stratégies RAG qui peuvent être cumulées pour améliorer la qualité et le taux de bonne réponse de votre agent IA ?
Le Retrieval Augmented Generation (RAG) transforme les agents IA en leur donnant accès à des données actualisées et spécifiques, mais la recherche vectorielle basique ne suffit plus. Découvrez comment combiner 3 à 5 stratégies RAG avancées pour créer des systèmes performants et réduire les hallucinations de 35%.
Avec l'explosion des applications LLM en production, les développeurs découvrent rapidement les limites du RAG classique : contexte manquant, chunks non pertinents, réponses imprécises. En 2025, 73% des systèmes RAG en production combinent désormais plusieurs stratégies pour obtenir des résultats fiables. Ce guide technique explore 11 approches éprouvées pour optimiser votre pipeline de récupération, des plus simples (reranking) aux plus sophistiquées (self-reflective RAG).
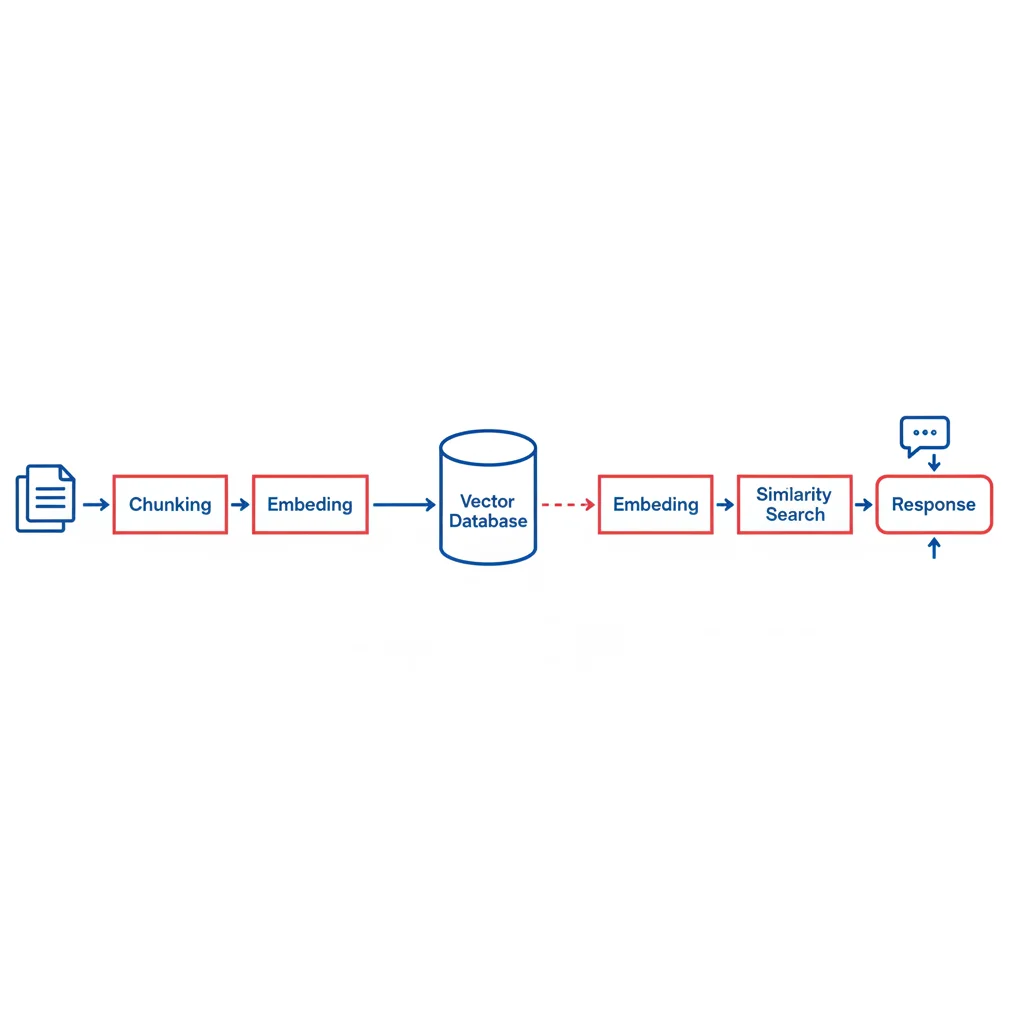
Qu'est-ce que le RAG et pourquoi l'optimiser ?
Le RAG (Retrieval Augmented Generation) est une technique qui combine la recherche d'information avec la génération de texte par LLM. Le principe fondamental : au lieu de demander au modèle de répondre uniquement à partir de ses connaissances internes, on lui fournit du contexte pertinent récupéré dans une base de données.
Le pipeline RAG classique se déroule en deux phases :
Phase 1 : Préparation des données (indexation)
- Chunking : Découpage des documents en segments de 200-1000 tokens
- Embedding : Transformation de chaque chunk en vecteur numérique dense (ex: 1536 dimensions avec OpenAI text-embedding-3-small)
- Stockage : Sauvegarde des vecteurs dans une base vectorielle (pgvector, Pinecone, Qdrant)
Phase 2 : Requête (runtime)
- Embedding de la requête : Conversion de la question utilisateur en vecteur
- Recherche de similarité : Comparaison vectorielle (cosine, L2) pour trouver les 3-5 chunks les plus proches
- Augmentation : Injection des chunks dans le prompt du LLM
- Génération : Le LLM produit une réponse contextualisée
Le problème du RAG basique : cette approche simple fonctionne pour des cas d'usage triviaux, mais échoue rapidement face à des données complexes. Les recherches de Google (2025) montrent que 66,1% des réponses deviennent incorrectes lorsque le contexte récupéré est insuffisant, contre seulement 10,2% sans contexte du tout. Le RAG mal configuré est pire que pas de RAG.
C'est pourquoi combiner 3 à 5 stratégies RAG avancées est devenu le standard en production. Voici les 11 techniques qui font la différence.
1. Reranking (Re-classement en deux étapes)
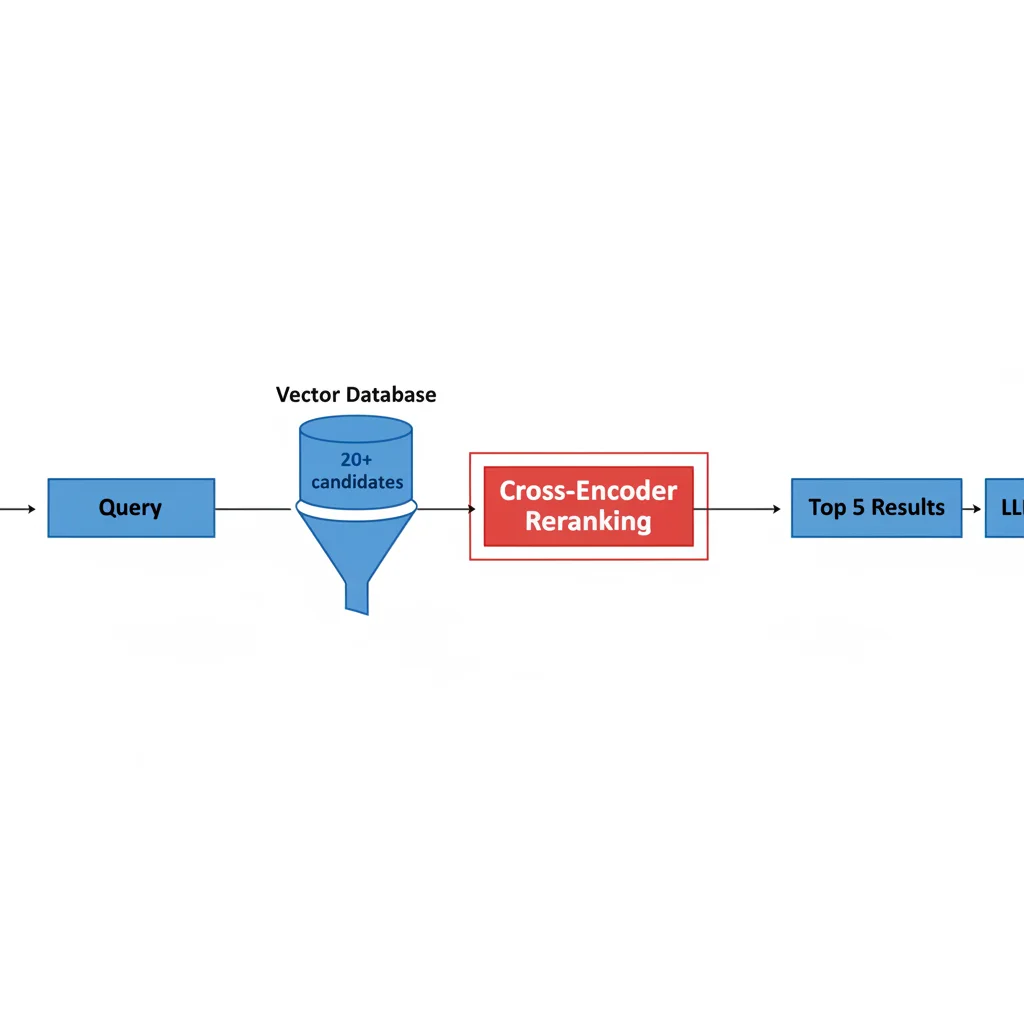
Le reranking est la stratégie RAG la plus efficace pour le meilleur rapport complexité/gain. Selon ZeroEntropy (2025), cette approche améliore la précision de +28% NDCG@10 par rapport à une recherche vectorielle simple.
NDCG@10 (Normalized Discounted Cumulative Gain) mesure la qualité du classement des 10 premiers résultats, en pondérant la pertinence selon la position.
Comment fonctionne le reranking ?
Au lieu de récupérer directement les 3-5 meilleurs chunks, le reranking utilise deux étapes :
- Étape 1 (Recall) : Recherche vectorielle rapide pour récupérer 20-50 candidats
- Étape 2 (Precision) : Filtrage avec un cross-encoder qui évalue chaque paire (requête, document) et retourne seulement les 5 meilleurs
Pourquoi cette approche fonctionne :
-
Bi-encoder : Encode la requête et chaque document séparément en vecteurs. Rapide (on pré-calcule les vecteurs documents une seule fois), mais la comparaison se limite à mesurer la distance entre deux vecteurs indépendants.
-
Cross-encoder : Analyse la requête ET le document ensemble dans le même modèle. Plus lent (calcul à chaque requête), mais capte les interactions sémantiques fines entre les deux textes.
Analogie : Le bi-encoder, c'est comme comparer deux CV en regardant leurs scores résumés. Le cross-encoder, c'est comme lire les deux CV côte à côte pour voir comment les compétences répondent précisément au poste.
Exemple de code Python avec Pydantic AI
from pydantic_ai import Agent
import psycopg2
from pgvector.psycopg2 import register_vector
agent = Agent('openai:gpt-4o',
system_prompt='Assistant RAG avec reranking.')
conn = psycopg2.connect("dbname=rag_db")
register_vector(conn)
@agent.tool
def search_with_reranking(query: str) -> str:
"""Recherche en deux étapes : rapide puis précise"""
# Étape 1 : Recherche vectorielle large (20 candidats)
with conn.cursor() as cur:
query_embedding = get_embedding(query)
cur.execute(
'SELECT content FROM chunks '
'ORDER BY embedding <=> %s LIMIT 20',
(query_embedding,)
)
candidates = [row[0] for row in cur.fetchall()]
# Étape 2 : Reranking avec cross-encoder
scored_results = []
for doc in candidates:
# Cross-encoder analyse query + doc ensemble
score = cross_encoder_score(query, doc)
scored_results.append((doc, score))
# Retourne top 5 après re-classement
scored_results.sort(key=lambda x: x[1], reverse=True)
return "\n\n".join([doc for doc, _ in scored_results[:5]])
Résultats mesurés
- +28% NDCG@10 (ZeroEntropy, 2025)
- -35% d'hallucinations LLM (Databricks, 2025)
- +48% de qualité avec pipeline hybride 3 étapes (Pinecone, 2025)
Modèles de reranking recommandés en 2025 :
- Voyage AI rerank-2.5 : Meilleur rapport qualité/latence (~600ms), instruction-following, context 32K tokens, +7.94% vs Cohere sur benchmarks standard
- Cohere Rerank v3.5 : Propriétaire, support 100+ langues, latence optimisée
- ZeroEntropy zerank-1 : Open-weight, meilleure pertinence absolue, 95% précision LLM avec 3x vitesse
- FlashRank : Open-source, ultra-rapide, modèles distillés (idéal pour contraintes budget)
2. Agentic RAG (RAG Agentique)
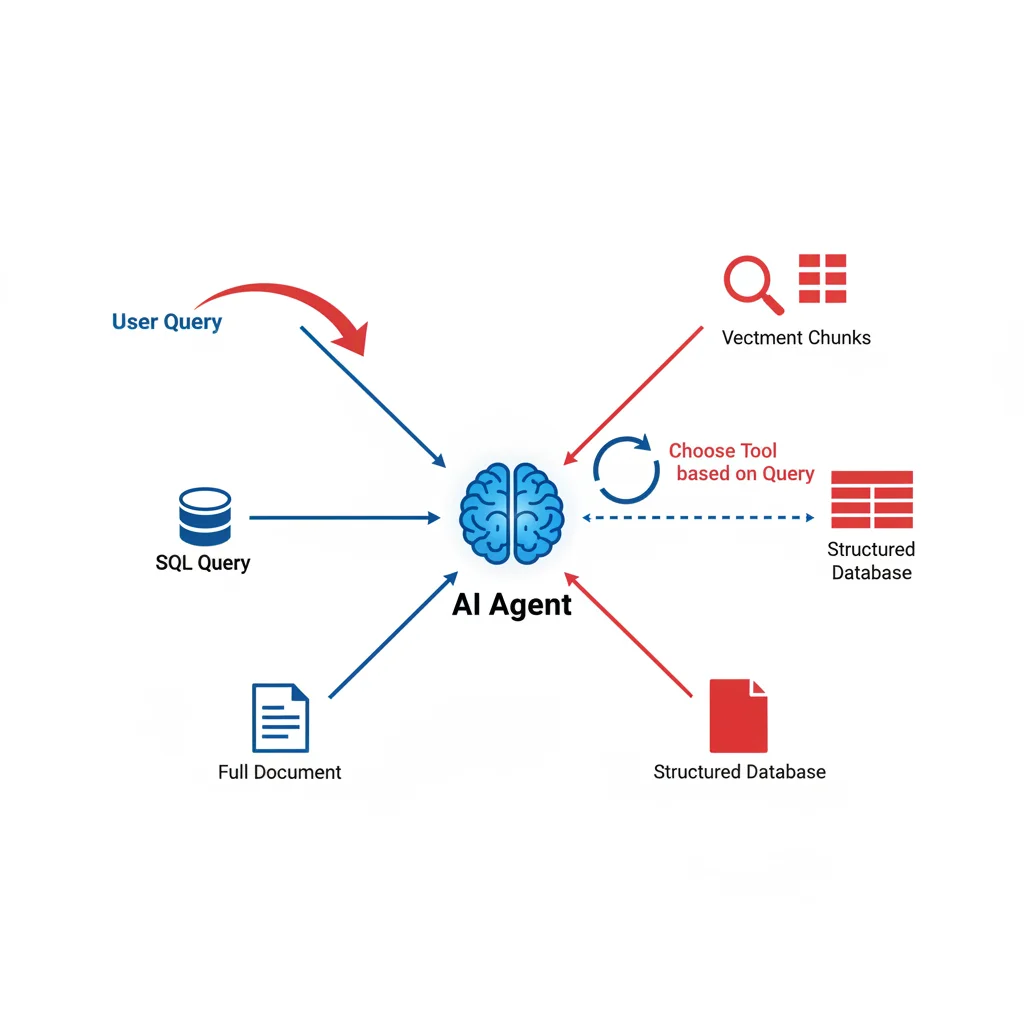
L'Agentic RAG confie au LLM le choix de l'outil de recherche adapté à chaque requête. Au lieu d'un pipeline fixe, l'agent décide dynamiquement entre recherche vectorielle, requête SQL, recherche web, ou combinaison de plusieurs sources.
Architecture agentic
L'agent dispose de plusieurs outils de recherche :
- Recherche vectorielle : Pour les données non structurées (documents, articles)
- Requête SQL : Pour les données structurées (bases relationnelles, métriques)
- Recherche hybride BM25 + vecteurs : Pour les requêtes nécessitant mots-clés ET sémantique
- Web search : Pour les informations récentes non indexées
BM25 (Best Matching 25) est un algorithme de recherche lexicale qui classe les documents selon la fréquence des termes de la requête, pondérée par leur rareté dans le corpus. Contrairement à la recherche vectorielle (sémantique), BM25 excelle pour les correspondances exactes de mots-clés.
Avantage : Le système s'adapte automatiquement au type de question. Une requête "Quels étaient nos revenus Q2 2024 ?" déclenchera SQL, tandis que "Explique le backpropagation" utilisera la recherche vectorielle.
Inconvénient : Moins prévisible, peut choisir le mauvais outil, coût LLM plus élevé (décision + génération).
Exemple de code Agentic RAG
from pydantic_ai import Agent
import psycopg2
from pgvector.psycopg2 import register_vector
agent = Agent('openai:gpt-4o',
system_prompt='Tu es un agent RAG avec accès à plusieurs outils.')
conn = psycopg2.connect("dbname=rag_db")
register_vector(conn)
@agent.tool
def vector_search(query: str) -> str:
"""Recherche dans la base de connaissances non structurée"""
with conn.cursor() as cur:
query_embedding = get_embedding(query)
cur.execute(
'SELECT content FROM chunks '
'ORDER BY embedding <=> %s LIMIT 3',
(query_embedding,)
)
return "\n".join([row[0] for row in cur.fetchall()])
@agent.tool
def sql_query(question: str) -> str:
"""Interroge la base de données structurée"""
# L'agent génère automatiquement la requête SQL
with conn.cursor() as cur:
cur.execute("SELECT * FROM sales WHERE quarter='Q2'")
return str(cur.fetchall())
@agent.tool
def web_search(query: str) -> str:
"""Recherche sur le web pour infos récentes"""
# Intégration Tavily, SerpAPI, etc.
return fetch_web_results(query)
# L'agent choisit automatiquement le(s) outil(s) pertinent(s)
result = agent.run_sync("Quels étaient nos ventes Q2 2024 ?")
# → L'agent utilisera probablement sql_query()
Cas d'usage idéal : Applications multi-domaines (chatbots entreprise, assistants de recherche) où les questions couvrent données structurées ET non structurées.
3. Knowledge Graphs (Graphes de Connaissances)
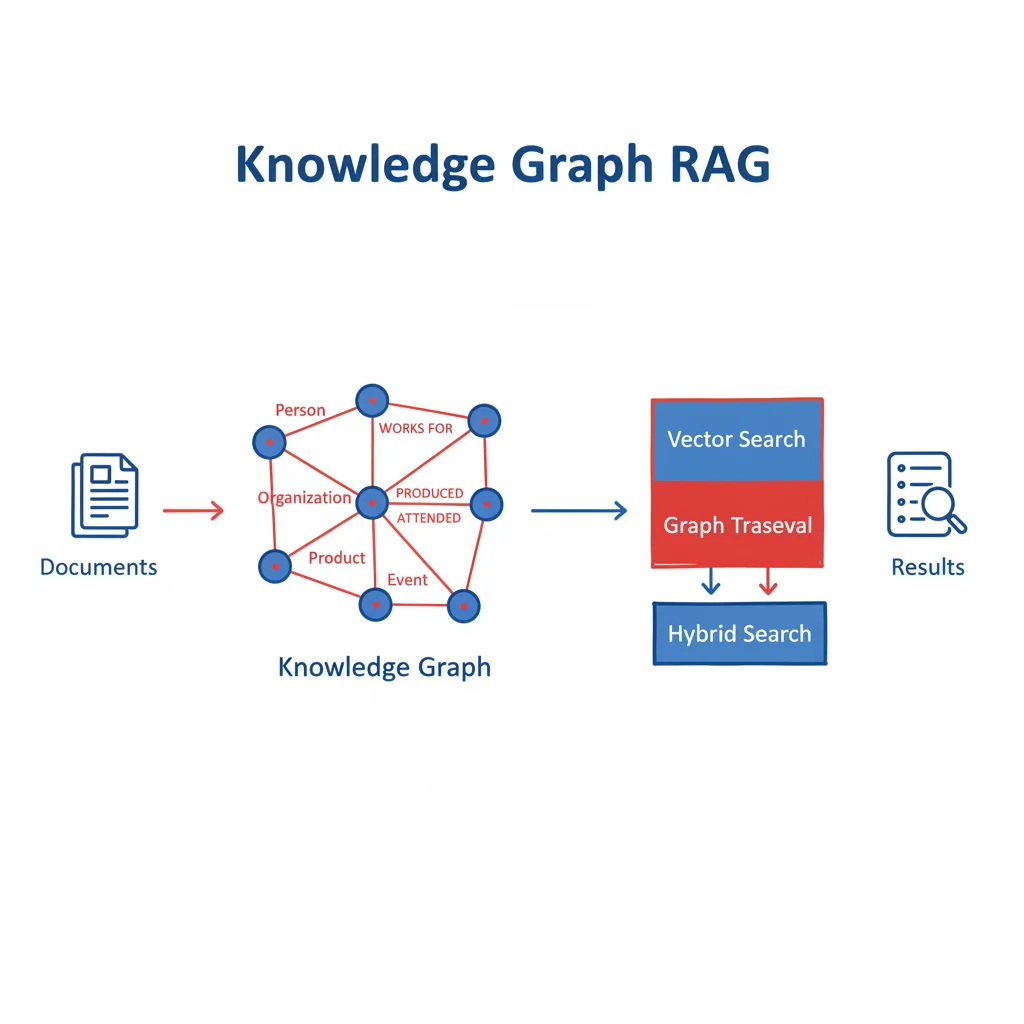
Les Knowledge Graphs combinent recherche vectorielle + traversée de graphe pour capturer les relations entre entités que les vecteurs seuls ne peuvent représenter.
Pourquoi les graphes de connaissances ?
Les embeddings vectoriels encodent la similarité sémantique, mais perdent les relations explicites :
- Hiérarchies organisationnelles (qui manage qui)
- Relations produits (composants, compatibilités)
- Chronologies d'événements (causes, conséquences)
- Dépendances techniques (architecture logicielle)
GraphRAG (Microsoft/Neo4j) résout ce problème en combinant :
- Recherche vectorielle HNSW pour trouver le point d'entrée
- Traversée de graphe pour suivre les relations et enrichir le contexte
- Embedding + relations explicites = contexte plus riche
Architecture GraphRAG avec Neo4j
Pipeline hybride vecteur + graphe :
- Indexation : Création du graphe de connaissances avec entités et relations
- Embedding : Vectorisation des nœuds pour recherche initiale
- Requête : Recherche vectorielle HNSW → Nœud d'entrée
- Traversée : Navigation des relations (Cypher query) pour contexte étendu
- Génération : LLM utilise nœud + voisinage pour réponse
Exemple de requête Cypher (Neo4j)
// Recherche vectorielle initiale
MATCH (doc:Document)
ORDER BY vector.similarity(doc.embedding, $query_embedding) DESC
LIMIT 5
// Traversée du graphe pour enrichir le contexte
MATCH (doc)-[:RELATES_TO|MENTIONS*1..2]-(related:Entity)
RETURN doc.content, collect(related.name) as context
Résultats mesurés (Neo4j, 2025) :
- Réponses plus précises sur données interconnectées
- Explicabilité : traçabilité du raisonnement via le graphe
- Meilleure gestion des questions multi-sauts ("Qui est le manager du chef de projet du produit X ?")
Limites :
- Performances dégradées en temps réel sur gros graphes
- Complexité de définition du schéma de graphe
- Pas optimal pour données hautement non structurées
4. Contextual Retrieval (Récupération Contextuelle Anthropic)

Le Contextual Retrieval d'Anthropic est une méthode révolutionnaire qui ajoute un préfixe contextuel à chaque chunk avant embedding. Résultat : 49% de réduction des échecs de récupération (Anthropic, 2024).
Le problème du chunking classique
Quand vous découpez un document en chunks de 500 tokens, chaque segment perd son contexte d'origine :
Document original : "Rapport financier Q2 2024 - Section Revenus" Chunk isolé : "Les ventes ont augmenté de 23% ce trimestre..."
Le chunk ne mentionne ni la période (Q2 2024), ni le sujet (revenus), ni le type de document (rapport financier). La recherche vectorielle échoue à le retrouver.
La solution Anthropic
Avant embedding, un LLM génère un préfixe contextuel pour chaque chunk :
Contexte : Ce chunk provient du rapport financier Q2 2024,
section revenus, page 3. Il décrit l'évolution des ventes
par rapport au trimestre précédent.
Chunk : Les ventes ont augmenté de 23% ce trimestre...
Ce chunk contextualisé est embedé et stocké. Lors de la recherche, la requête "revenus Q2 2024" match beaucoup mieux.
Implémentation avec Claude
from pydantic_ai import Agent
import psycopg2
from pgvector.psycopg2 import register_vector
agent = Agent('anthropic:claude-3-5-sonnet')
conn = psycopg2.connect("dbname=rag_db")
register_vector(conn)
def add_context_to_chunk(document: str, chunk: str) -> str:
"""Génère un préfixe contextuel avec un LLM"""
prompt = f"""Document complet (extrait) : {document[:500]}...
Chunk à contextualiser : {chunk}
Fournis un contexte bref (2-3 phrases) expliquant ce que
traite ce chunk par rapport au document entier."""
context = llm_generate(prompt)
return f"{context}\n\n{chunk}"
def ingest_document(text: str, metadata: dict):
chunks = [text[i:i+500] for i in range(0, len(text), 500)]
with conn.cursor() as cur:
for chunk in chunks:
# Ajout du contexte AVANT embedding
contextualized = add_context_to_chunk(text, chunk)
# Embedding de la version contextualisée
embedding = get_embedding(contextualized)
cur.execute(
'INSERT INTO chunks (content, embedding) '
'VALUES (%s, %s)',
(contextualized, embedding)
)
conn.commit()
Résultats benchmarks Anthropic (2024)
Anthropic a testé sur plusieurs domaines (code, fiction, ArXiv, science) avec l'embedding Gemini Text 004 et top-20 chunks :
| Technique | Taux d'échec (rappel@20) | Amélioration |
|---|---|---|
| Embeddings seuls | 5,7% | Baseline |
| Contextual Embeddings | 3,7% | -35% échecs |
| Contextual Embeddings + BM25 | 2,9% | -49% échecs |
| + Reranking | 1,9% | -67% échecs |
Coût : Avec chunks de 800 tokens, documents de 8000 tokens, instructions de 50 tokens, et contexte de 100 tokens, le coût one-time est $1,02 par million de tokens de documents (Claude 3.5 Sonnet).
Recommandation : Coûteux à l'indexation mais ROI excellent si vos données sont complexes et que la précision est critique.
5. Query Expansion (Expansion de Requête)
Query Expansion enrichit la requête utilisateur avec plus de contexte et termes associés avant de lancer la recherche.
Principe
Les utilisateurs posent souvent des questions courtes et ambiguës :
- "Comment marche le RAG ?" → Manque contexte technique
- "Problème de performance" → Quel type de performance ?
Query Expansion utilise un LLM pour reformuler/enrichir :
Requête originale : "Comment marche le RAG ?"
Requête expandée : "Comment fonctionne le Retrieval Augmented
Generation (RAG) pour les modèles de langage ? Explique le
processus de chunking, embedding, recherche vectorielle et
génération augmentée par contexte."
Implémentation simple
@agent.tool
def search_with_expansion(query: str) -> str:
"""Recherche avec expansion de requête"""
# Expansion de la requête
expansion_prompt = f"""Requête : {query}
Reformule cette requête en ajoutant :
- Les termes techniques pertinents
- Le contexte implicite
- Les synonymes utiles
Retourne seulement la requête enrichie."""
expanded_query = llm_generate(expansion_prompt)
# Recherche avec requête enrichie
embedding = get_embedding(expanded_query)
with conn.cursor() as cur:
cur.execute(
'SELECT content FROM chunks '
'ORDER BY embedding <=> %s LIMIT 5',
(embedding,)
)
return "\n".join([row[0] for row in cur.fetchall()])
Avantages :
- Simple à implémenter (un appel LLM)
- Améliore significativement les requêtes courtes
- Capture l'intention utilisateur
Inconvénients :
- Coût : +1 appel LLM par requête
- Peut sur-spécifier et manquer des résultats pertinents
- Latence augmentée
6. Multi-Query RAG
Multi-Query RAG génère 3-5 variations de la requête utilisateur et lance des recherches parallèles, puis dédoublonne et fusionne les résultats.
Pourquoi plusieurs requêtes ?
Une seule formulation peut manquer des documents pertinents selon l'angle d'approche. Multi-Query élargit la couverture :
Requête originale : "Comment optimiser les performances RAG ?"
Variations générées :
- "Quelles techniques améliorent la vitesse des systèmes RAG ?"
- "Comment réduire la latence de récupération dans les pipelines RAG ?"
- "Méthodes d'optimisation pour Retrieval Augmented Generation"
- "Best practices pour accélérer les recherches vectorielles"
Implémentation
@agent.tool
def multi_query_search(query: str) -> str:
"""Génère plusieurs variations et fusionne résultats"""
# Génération de 4 variations
variations_prompt = f"""Requête : {query}
Génère 3 reformulations différentes de cette requête,
chacune avec un angle légèrement différent.
Format : une requête par ligne."""
variations = llm_generate(variations_prompt).split('\n')
all_queries = [query] + variations # 4 requêtes total
# Recherche parallèle
all_results = []
for q in all_queries:
embedding = get_embedding(q)
with conn.cursor() as cur:
cur.execute(
'SELECT content FROM chunks '
'ORDER BY embedding <=> %s LIMIT 5',
(embedding,)
)
all_results.extend([row[0] for row in cur.fetchall()])
# Dédoublonnage
unique_results = list(set(all_results))[:5]
return "\n\n".join(unique_results)
Cas d'usage :
- Questions ambiguës ou larges
- Recherche exploratoire
- Besoin de couverture maximale
Limite : Coût computationnel 3-4x supérieur (embeddings + recherches multiples).
7. Context-Aware Chunking (Découpage Contextuel)
Le découpage classique (tous les X tokens) brise les frontières sémantiques. Le Context-Aware Chunking découpe intelligemment selon la structure et la similarité sémantique.
Le problème du chunking fixe
Chunk 1 : "...fin du paragraphe sur les réseaux de neurones.
Introduction aux transformers : Les transformers..."
Chunk 2 : "...ont révolutionné le NLP en 2017. Architecture :
Le modèle utilise..."
Le chunk 1 mélange deux sujets différents. Le chunk 2 commence au milieu d'une idée.
Chunking contextuel intelligent
Algorithme :
- Détection de la structure (titres, sections, paragraphes)
- Calcul de similarité sémantique entre phrases consécutives
- Découpage aux frontières de faible similarité (changement de topic)
- Respect de tailles min/max (200-1000 tokens)
Résultat : Chunks cohérents qui correspondent à des unités sémantiques complètes.
Implémentation simplifiée
def context_aware_chunking(text: str, max_size=800) -> list:
"""Découpe selon similarité sémantique"""
sentences = split_into_sentences(text)
chunks = []
current_chunk = []
for i, sentence in enumerate(sentences):
current_chunk.append(sentence)
# Vérifier si on doit couper ici
if i < len(sentences) - 1:
# Similarité entre chunk actuel et phrase suivante
chunk_embedding = get_embedding(' '.join(current_chunk))
next_embedding = get_embedding(sentences[i+1])
similarity = cosine_similarity(chunk_embedding, next_embedding)
# Si similarité faible OU taille max atteinte
if similarity < 0.7 or len(' '.join(current_chunk)) > max_size:
chunks.append(' '.join(current_chunk))
current_chunk = []
if current_chunk:
chunks.append(' '.join(current_chunk))
return chunks
Avantages :
- Gratuit (pas d'appel LLM additionnel)
- Préserve la cohérence sémantique
- Améliore significativement la pertinence
Framework recommandé : Docling (IBM Research) pour découpage avancé avec détection de structure (titres, tableaux, figures).
Exemple avec Docling HybridChunker
Docling combine plusieurs approches en un seul chunker intelligent :
from docling.chunking import HybridChunker
from transformers import AutoTokenizer
# Tokenizer pour contrôle précis des tokens
tokenizer = AutoTokenizer.from_pretrained(
"sentence-transformers/all-MiniLM-L6-v2"
)
# HybridChunker : structure + sémantique + tokens
chunker = HybridChunker(
tokenizer=tokenizer,
max_tokens=512, # Limite embedding model
merge_peers=True # Fusionne petits chunks adjacents
)
# Chunking intelligent
chunks = list(chunker.chunk(dl_doc=docling_document))
# Chaque chunk inclut son contexte (hiérarchie titres)
for chunk in chunks:
contextualized = chunker.contextualize(chunk)
# → "# Section principale > ## Sous-section\n\nContenu du chunk..."
Avantages de Docling :
- Token-aware : Respecte les limites des modèles d'embedding
- Structure-aware : Préserve titres, tableaux, listes
- Contextualisé : Chaque chunk hérite de sa hiérarchie de titres
8. Late Chunking (Découpage Tardif)
Late Chunking inverse l'ordre des opérations : embed d'abord le document complet, PUIS découpe. Chaque chunk conserve le contexte global.
Chunking classique vs Late Chunking
Classique : Document → Chunks → Embed chaque chunk → Stockage
Late Chunking : Document → Embed complet → Chunks avec contexte → Stockage
Comment ça marche techniquement ?
- Embedding du document complet avec un modèle transformer (ex: BERT, T5)
- Récupération des états cachés (hidden states) de toutes les positions
- Découpage : Chaque chunk hérite des états cachés correspondants
- Pooling : Agrégation des états pour créer l'embedding du chunk
Avantage : Chaque chunk "sait" ce qui vient avant et après dans le document.
Cas d'usage
- Documents avec forte cohérence narrative (rapports, articles scientifiques)
- Besoin de préserver les références croisées
- Textes techniques avec dépendances entre sections
Limite : Complexité technique élevée, nécessite modèles transformer avec accès aux hidden states, coût computationnel supérieur.
9. Hierarchical RAG (RAG Hiérarchique)
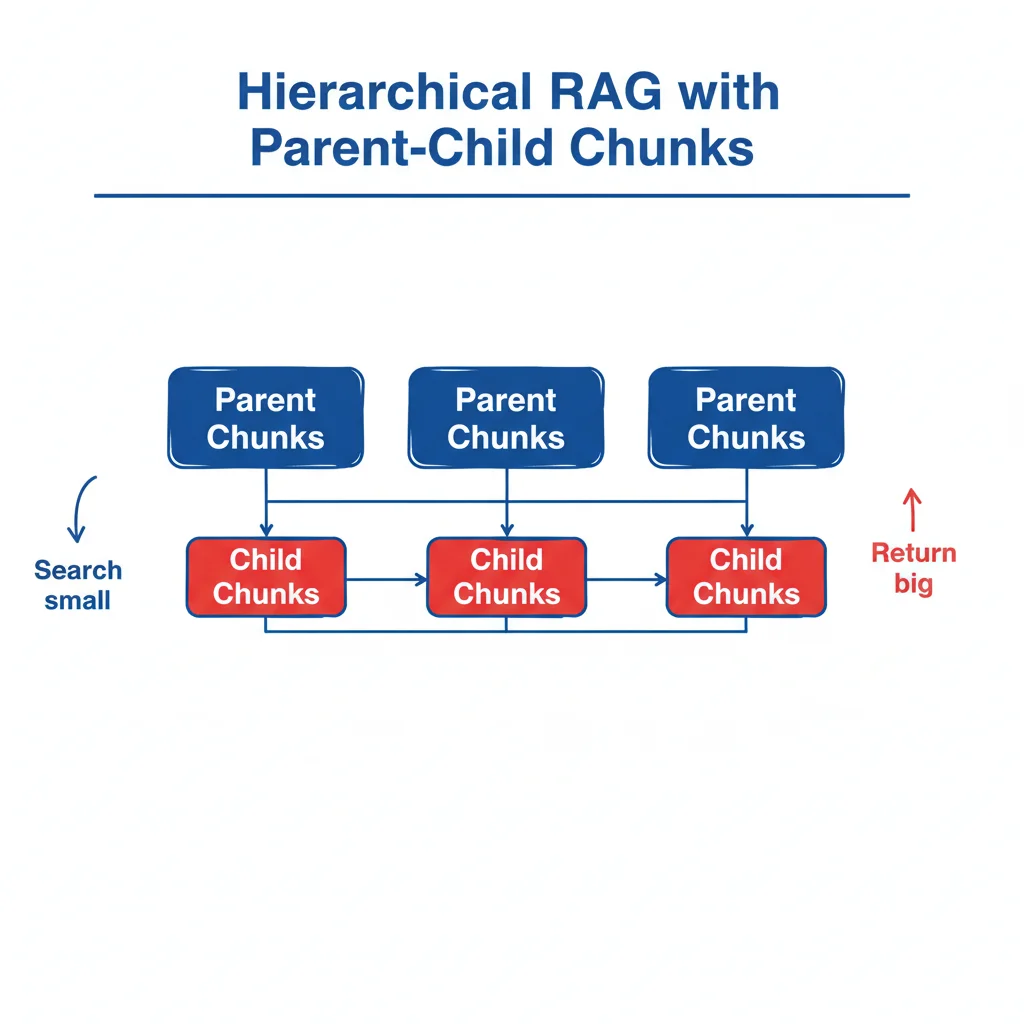
Hierarchical RAG crée des relations parent-enfant entre chunks : recherche précise sur petits chunks, retourne les parents pour contexte étendu. "Search small, return big".
Architecture hiérarchique
Deux niveaux de chunks :
- Chunks enfants (200-500 tokens) : Granularité fine, optimisés pour la recherche
- Chunks parents (1500-2500 tokens) : Contexte étendu, retournés au LLM
Métadonnées enrichies : Chaque parent contient metadata (titre section, type de contenu, position dans le document).
Implémentation avec PostgreSQL
# Table parent_chunks
CREATE TABLE parent_chunks (
id SERIAL PRIMARY KEY,
content TEXT,
metadata JSONB -- {heading, type, position}
);
# Table child_chunks
CREATE TABLE child_chunks (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(1536),
parent_id INTEGER REFERENCES parent_chunks(id)
);
Code de recherche hiérarchique
@agent.tool
def hierarchical_search(query: str) -> str:
"""Recherche enfants, retourne parents avec contexte"""
query_embedding = get_embedding(query)
with conn.cursor() as cur:
# Recherche sur les enfants (précision)
cur.execute('''
SELECT p.content, p.metadata
FROM child_chunks c
JOIN parent_chunks p ON c.parent_id = p.id
ORDER BY c.embedding <=> %s
LIMIT 3
''', (query_embedding,))
# Retourne les parents avec heading
results = []
for content, metadata in cur.fetchall():
heading = metadata.get('heading', 'Section')
results.append(f"[{heading}]\n{content}")
return "\n\n".join(results)
Résultats : Équilibre optimal précision/contexte. La recherche fine sur petits chunks assure la pertinence, les parents fournissent le contexte nécessaire au LLM.
Cas d'usage :
- Documentation technique structurée
- Livres, rapports longs
- Knowledge bases avec hiérarchie claire
10. Self-Reflective RAG (RAG Auto-Réflexif)

Self-Reflective RAG implémente une boucle d'auto-correction : recherche → évaluation (note 1-5) → si insuffisant, raffiner et re-chercher.
Pipeline auto-réflexif
- Recherche initiale : Récupération de 3-5 chunks
- Auto-évaluation : LLM note la pertinence des résultats (1-5)
- Décision : Si note < 3, raffiner la requête et relancer
- Itération : Maximum 3 itérations
- Génération : Réponse finale avec meilleurs résultats
Implémentation
@agent.tool
def self_reflective_search(query: str, max_iterations=3) -> str:
"""Recherche avec auto-correction itérative"""
current_query = query
for iteration in range(max_iterations):
# Recherche
embedding = get_embedding(current_query)
with conn.cursor() as cur:
cur.execute(
'SELECT content FROM chunks '
'ORDER BY embedding <=> %s LIMIT 5',
(embedding,)
)
results = [row[0] for row in cur.fetchall()]
# Auto-évaluation
eval_prompt = f"""Requête : {query}
Résultats récupérés :
{chr(10).join(results)}
Note la pertinence de ces résultats pour répondre à la requête.
Échelle : 1 (non pertinent) à 5 (très pertinent).
Retourne seulement le chiffre."""
score = int(llm_generate(eval_prompt))
# Si score satisfaisant, terminer
if score >= 3:
return "\n\n".join(results)
# Sinon, raffiner la requête
refine_prompt = f"""Requête originale : {query}
Les résultats obtenus ne sont pas satisfaisants (score {score}/5).
Reformule la requête pour améliorer la recherche."""
current_query = llm_generate(refine_prompt)
# Après max_iterations, retourner dernier résultat
return "\n\n".join(results)
Avantages :
- S'améliore itérativement
- Potentiellement la meilleure précision
- Résilience face aux requêtes difficiles
Inconvénients :
- Le plus lent : 2-4 appels LLM + recherches multiples
- Coût élevé en production
- Pas de garantie de convergence
Recommandation : Réserver aux cas critiques où la précision prime sur la latence.
11. Fine-tuned Embeddings (Embeddings Entraînés)
Fine-tuned Embeddings consiste à entraîner un modèle d'embedding spécifique à votre domaine pour améliorer la précision de 5-10% par rapport aux embeddings génériques.
Pourquoi fine-tuner ?
Les modèles d'embedding génériques (OpenAI text-embedding-3, sentence-transformers) sont entraînés sur des corpus généralistes. Ils performent moins bien sur :
- Jargon technique spécifique (médical, juridique, financier)
- Langage interne à l'entreprise
- Domaines hyper-spécialisés (bioinformatique, physique quantique)
Fine-tuning adapte le modèle à votre vocabulaire et vos patterns sémantiques.
Processus de fine-tuning
-
Création du dataset d'entraînement : Paires (requête, passage pertinent)
- Minimum 1000 paires, idéalement 10 000+
- Exemples réels de recherches réussies
- Annotations de pertinence
-
Choix du modèle de base :
- sentence-transformers/all-MiniLM-L6-v2 (léger)
- BAAI/bge-large-en-v1.5 (performant)
- intfloat/e5-large-v2 (polyvalent)
-
Fine-tuning avec loss contrastive (ex: MultipleNegativesRankingLoss)
-
Évaluation : Métrique NDCG@10, Recall@5 sur set de validation
Recall@5 évalue la proportion de documents pertinents retrouvés dans les 5 premiers résultats.
Exemple avec Sentence-Transformers
from sentence_transformers import SentenceTransformer, InputExample, losses
from torch.utils.data import DataLoader
# Chargement du modèle de base
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Dataset d'entraînement (exemples)
train_examples = [
InputExample(texts=['query1', 'passage pertinent 1']),
InputExample(texts=['query2', 'passage pertinent 2']),
# ... 10 000+ exemples
]
# DataLoader
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
# Loss contrastive
train_loss = losses.MultipleNegativesRankingLoss(model)
# Fine-tuning
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=3,
warmup_steps=100
)
# Sauvegarde
model.save('models/custom-rag-embeddings')
Résultats attendus
- +5-10% précision sur domaine cible (benchmarks académiques)
- Amélioration significative sur queries spécifiques au domaine
- Embeddings plus petits possibles (compression)
Coûts :
- Temps de création dataset : 40-100 heures humaines
- Entraînement GPU : 2-10 heures (selon taille modèle et dataset)
- Maintenance : Re-entraînement périodique quand le domaine évolue
Recommandation : Réservé aux cas où :
- Le domaine est très spécialisé
- Volume de données suffisant pour entraînement
- ROI justifié (applications critiques, fort volume de requêtes)
Choisir son modèle d'embedding
Le choix du modèle d'embedding impacte directement la qualité de récupération. En 2025, Voyage AI domine les benchmarks, surpassant OpenAI de +9.74% sur les évaluations multilingues (MTEB).
Comparatif des modèles d'embedding 2025
| Modèle | Performance | Prix/1M tokens | Context | Dimensions | Forces |
|---|---|---|---|---|---|
| Voyage voyage-3-large | SOTA | $0.12 | 32K | 1024 | #1 sur 100 datasets, 26 langues |
| Voyage voyage-3.5 | Excellent | $0.06 | 32K | 1024 | Meilleur rapport qualité/prix |
| Voyage voyage-3.5-lite | Très bon | $0.02 | 32K | 512 | Ultra économique |
| OpenAI text-embedding-3-large | Bon | $0.13 | 8K | 3072 | Écosystème, simplicité |
| OpenAI text-embedding-3-small | Correct | $0.02 | 8K | 1536 | Budget serré |
| multilingual-e5-large | Très bon | Gratuit | 512 | 1024 | Open-source, multilingue |
| Sentence-Camembert-large | Top FR | Gratuit | 512 | 1024 | Optimisé français |
Recommandations par cas d'usage
Pour le français et le multilingue :
- Voyage voyage-3-large : Meilleure précision absolue, surpasse OpenAI de +9.74% sur MTEB multilingue
- multilingual-e5-large : Alternative open-source performante
Pour l'anglais uniquement :
- Voyage voyage-3.5 : Optimal rapport qualité/prix
- OpenAI text-embedding-3-large : Si vous êtes déjà dans l'écosystème OpenAI
Budget contraint :
- Voyage voyage-3.5-lite : $0.02/1M tokens avec 32K context
- Sentence-Camembert-large : Gratuit, excellent pour le français
Multimodal (images + texte) :
- Voyage voyage-multimodal-3.5 : Embeddings unifiés pour PDFs, slides, tableaux, figures
Exemple de configuration Voyage AI
import voyageai
# Client Voyage AI
vo = voyageai.Client() # VOYAGE_API_KEY dans env
def get_embedding(text: str) -> list[float]:
"""Génère un embedding avec Voyage AI"""
result = vo.embed(
texts=[text],
model="voyage-3-large", # ou voyage-3.5-lite pour budget
input_type="document" # ou "query" pour les requêtes
)
return result.embeddings[0]
# Pour les requêtes (optimisé différemment)
def get_query_embedding(query: str) -> list[float]:
result = vo.embed(
texts=[query],
model="voyage-3-large",
input_type="query"
)
return result.embeddings[0]
Astuce : Voyage AI distingue
input_type="document"etinput_type="query"pour optimiser les embeddings selon le contexte. Utilisez "document" à l'indexation et "query" à la recherche.
Migration OpenAI → Voyage AI
Si vous utilisez déjà OpenAI, la migration est simple :
# Avant (OpenAI)
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
embedding = response.data[0].embedding
# Après (Voyage AI)
import voyageai
vo = voyageai.Client()
result = vo.embed(texts=[text], model="voyage-3.5-lite")
embedding = result.embeddings[0]
Impact : +9.74% précision, -54% coût ($0.02 vs $0.02 mais 32K vs 8K context).
Tableau comparatif des 11 stratégies RAG
| Stratégie | Complexité | Coût (runtime) | Gain précision | Latence | Cas d'usage idéal |
|---|---|---|---|---|---|
| 1. Reranking | Faible | Moyen | +28-48% | Basse | Standard, meilleur rapport qualité/simplicité |
| 2. Agentic RAG | Moyenne | Élevé | Variable | Moyenne | Multi-domaines (structuré + non structuré) |
| 3. Knowledge Graphs | Élevée | Élevé | +15-30%* | Moyenne-Haute | Données interconnectées, relations complexes |
| 4. Contextual Retrieval | Moyenne | Faible (one-time) | -49% échecs | Basse | Tous types, ROI excellent |
| 5. Query Expansion | Faible | Moyen | +10-20% | Moyenne | Requêtes courtes/ambiguës |
| 6. Multi-Query RAG | Faible | Élevé | +15-25% | Haute | Recherche exploratoire, couverture maximale |
| 7. Context-Aware Chunking | Moyenne | Gratuit | +10-15% | Basse | Tous types, preprocessing intelligent |
| 8. Late Chunking | Élevée | Élevé | +5-10% | Moyenne | Documents narratifs cohérents |
| 9. Hierarchical RAG | Moyenne | Faible | +15-20% | Basse | Documentation structurée, longs documents |
| 10. Self-Reflective RAG | Moyenne | Très élevé | +20-35% | Très haute | Cas critiques, précision maximale |
| 11. Fine-tuned Embeddings | Très élevée | Moyen | +5-10% | Basse | Domaines hyper-spécialisés |
* Sur données relationnelles, moins d'impact sur texte non structuré
Stratégies émergentes à surveiller (2025-2026)
Au-delà des 11 stratégies établies, plusieurs approches gagnent en traction :
Corrective RAG (CRAG)
Corrective RAG ajoute une étape d'évaluation avant la génération : si les documents récupérés sont jugés insuffisants (score de pertinence < seuil), le système déclenche automatiquement une recherche web de secours.
Pipeline CRAG :
- Récupération classique → Documents candidats
- Évaluation : LLM note la pertinence (1-5)
- Si score < 3 → Fallback recherche web
- Génération avec meilleurs documents
Avantage : Réduit drastiquement les hallucinations sur questions hors-domaine.
Adaptive RAG
Adaptive RAG classifie la complexité de chaque requête avant de choisir la stratégie :
- Simple (salutations, questions factuelles) → Réponse directe LLM, pas de retrieval
- Moyenne (recherche factuelle) → RAG classique
- Complexe (multi-sources, raisonnement) → Multi-Query + Reranking
Avantage : Optimise coût et latence en évitant le retrieval inutile.
HopRAG (Multi-Hop Reasoning)
Pour les questions nécessitant plusieurs étapes de raisonnement, HopRAG chaîne les recherches :
- "Qui est le CEO de la société qui a racheté Voyage AI ?"
- Étape 1 : Recherche "acquisition Voyage AI" → MongoDB
- Étape 2 : Recherche "CEO MongoDB" → Dev Ittycheria
Cas d'usage : Questions complexes nécessitant synthèse de plusieurs sources.
Ces stratégies émergentes sont prometteuses mais ajoutent de la complexité. Recommandation : Maîtrisez d'abord le trio Reranking + Contextual Retrieval + Context-Aware Chunking avant d'explorer ces approches avancées.
Comment combiner les stratégies RAG ?
L'erreur classique : Implémenter les 11 stratégies en même temps. Résultat : complexité ingérable, coûts explosifs, gains marginaux.
La bonne approche : Commencer par 3 stratégies complémentaires, mesurer l'impact, itérer.
Stack recommandée pour débuter (2026)
Combinaison gagnante : Reranking + Contextual Retrieval + Context-Aware Chunking
- Context-Aware Chunking (preprocessing) : Découpage intelligent préservant cohérence
- Contextual Retrieval (indexation) : Ajout de préfixes contextuels aux chunks
- Reranking (runtime) : Récupération large + filtrage précis
Résultats cumulés attendus :
- 35-49% réduction échecs (Contextual Retrieval)
- +28-48% précision (Reranking)
- Chunks cohérents (Context-Aware)
- Total : ~60-70% amélioration vs RAG basique
Stack technique recommandée
Base de données : PostgreSQL + pgvector
- Combine données relationnelles et vecteurs
- ACID transactions
- Mature et scalable jusqu'à 1M vecteurs
- Extensions : pgvector (vecteurs), pg_trgm (BM25)
Framework IA : Pydantic AI (Python)
- Type-safe avec Pydantic
- Support multi-providers (OpenAI, Anthropic, etc.)
- Pattern
@agent.toolélégant - Validation automatique des entrées/sorties
Embeddings : Voyage AI voyage-3.5 (1024 dim) ou voyage-3.5-lite (512 dim)
- SOTA sur benchmarks multilingues (+9.74% vs OpenAI)
- Excellent pour le français et l'anglais
- Context 32K tokens, $0.06/1M (ou $0.02 pour lite)
- Alternative économique : OpenAI text-embedding-3-small
Reranker : Voyage AI rerank-2.5 (meilleur rapport qualité/latence) ou FlashRank (open-source)
Évolution progressive
Phase 1 (MVP) : Reranking seul
- Gain : +28% précision
- Coût : Minimal
Phase 2 (Production) : + Contextual Retrieval
- Gain additionnel : +20-30%
- Coût : One-time à l'indexation
Phase 3 (Optimisation) : + Context-Aware Chunking
- Gain additionnel : +10-15%
- Coût : Gratuit
Phase 4 (Avancé - optionnel) : + Agentic RAG ou Hierarchical RAG
- Selon cas d'usage spécifique
- Mesurer l'impact avant de généraliser
FAQ - Questions fréquentes sur les stratégies RAG
Quelle est la meilleure stratégie RAG pour commencer en 2026 ?
Le Reranking est la stratégie la plus efficace pour débuter : +28% de précision avec un rapport complexité/gain imbattable. Implémentation simple (ajout cross-encoder en 2e étape), coût modéré, gains immédiats mesurables. Combinez-le avec Contextual Retrieval d'Anthropic pour atteindre 60-70% d'amélioration.
Combien de stratégies RAG faut-il combiner ?
3 à 5 stratégies maximum selon nos tests en production. Au-delà, la complexité augmente plus vite que les gains. Commencez par le trio gagnant : Context-Aware Chunking (preprocessing) + Contextual Retrieval (indexation) + Reranking (runtime). Ajoutez ensuite Agentic RAG ou Hierarchical RAG selon vos besoins spécifiques.
Quel est le coût du Contextual Retrieval d'Anthropic ?
$1,02 par million de tokens de documents (one-time, à l'indexation). Avec chunks de 800 tokens et contexte de 100 tokens par chunk via Claude 3.5 Sonnet. Ce coût est amorti sur la durée de vie du système et largement compensé par la réduction de 49% des échecs de récupération. Pour un corpus de 10 000 documents (50M tokens), comptez ~$50 d'indexation.
Pourquoi le reranking améliore-t-il autant la précision ?
Les cross-encoders analysent query et document ensemble, capturant des interactions sémantiques riches que les bi-encoders (embeddings classiques) ne peuvent pas représenter. Les bi-encoders compressent tout le sens d'un document en un seul vecteur, perdant de l'information. Les cross-encoders traitent les deux textes conjointement via attention mechanism, d'où +28-48% de précision selon ZeroEntropy et Pinecone (2025).
PostgreSQL pgvector ou base vectorielle dédiée (Pinecone, Qdrant) ?
PostgreSQL + pgvector jusqu'à 1 million de vecteurs, puis base dédiée. Avantages pgvector : combine données relationnelles et vecteurs, ACID transactions, infrastructure existante, coût réduit. Au-delà de 10M vecteurs, les bases dédiées offrent 10-100x vitesse supérieure grâce aux index spécialisés (product quantization). Pour 90% des cas d'usage, pgvector suffit largement.
Le Fine-tuning des embeddings en vaut-il la peine ?
Seulement pour domaines hyper-spécialisés (médical, juridique, scientifique) avec vocabulaire unique. Gain typique : +5-10% précision, mais coût élevé (40-100h création dataset, maintenance continue). Avant de fine-tuner, testez d'abord Contextual Retrieval + Reranking : vous obtiendrez probablement 60-70% d'amélioration sans le coût d'entraînement. Le fine-tuning est la dernière optimisation, pas la première.
Comment mesurer l'efficacité de mes stratégies RAG ?
Métriques clés à tracker : Recall@K (% documents pertinents récupérés), NDCG@10 (précision du classement), taux d'hallucination LLM (vérification factuelle), latence P95 (expérience utilisateur). Créez un golden dataset de 100-500 paires (question, réponse attendue) représentatives. Mesurez avant/après chaque stratégie ajoutée. Selon AWS (2025), les systèmes RAG en production trackent ces 4 métriques en continu.
Conclusion : Votre roadmap RAG optimisée 2026
Les 11 stratégies RAG présentées dans ce guide transforment un système basique en pipeline de récupération de classe production. Les données 2025 sont claires : les implémentations qui combinent Contextual Retrieval (-49% échecs), Reranking (+28-48% précision) et chunking intelligent réduisent les hallucinations de 35% tout en améliorant la précision de 60-70%.
Notre recommandation finale pour Hoko :
- Commencez simple : Reranking seul
- Ajoutez le contexte : Contextual Retrieval Anthropic
- Optimisez le preprocessing : Context-Aware Chunking avec Docling
- Stack technique : PostgreSQL + pgvector, Pydantic AI, OpenAI embeddings, Voyage AI rerank-2.5
- Mesurez : Recall@5, NDCG@10, latence P95, taux d'hallucination
Évitez : Implémenter les 11 stratégies simultanément, fine-tuning prématuré, bases vectorielles dédiées avant 1M vecteurs, Self-Reflective RAG en production (trop lent).
Chez Hoko, nous accompagnons les entreprises dans l'implémentation de systèmes RAG optimisés adaptés à leurs données et contraintes spécifiques. Notre expertise en IA et développement sur mesure nous permet de déployer des pipelines de récupération performants en 2-4 semaines, avec mesure d'impact et itérations basées sur vos métriques métier.
Vous souhaitez optimiser vos agents IA avec des stratégies RAG avancées ? Contactez l'équipe Hoko pour un audit technique de votre système actuel et une roadmap d'implémentation personnalisée.
Sources :
- Anthropic - Introducing Contextual Retrieval
- ZeroEntropy - Ultimate Guide to Choosing the Best Reranking Model in 2025
- Voyage AI - Rerankers Documentation
- Voyage AI - voyage-3-large: State-of-the-Art Embedding Model
- MTEB Leaderboard - Hugging Face
- Neo4j - Knowledge Graph vs. Vector RAG
- PostgreSQL pgvector as Vector Database for RAG
- Pinecone - Rerankers and Two-Stage Retrieval
- Google Research - Deeper insights into retrieval augmented generation
- Docling - IBM Research Document Processing
- arXiv - Enhancing Retrieval-Augmented Generation: A Study of Best Practices
- Chitika - Retrieval-Augmented Generation (RAG): 2025 Definitive Guide